アーキテクチャ
あなたのアプリは既にデータを生み出している。2つのストレージ世界。1つのパイプライン。1つのライブラリ。移行なし、再プラットフォーム化なし — 今あるものを読むだけ。
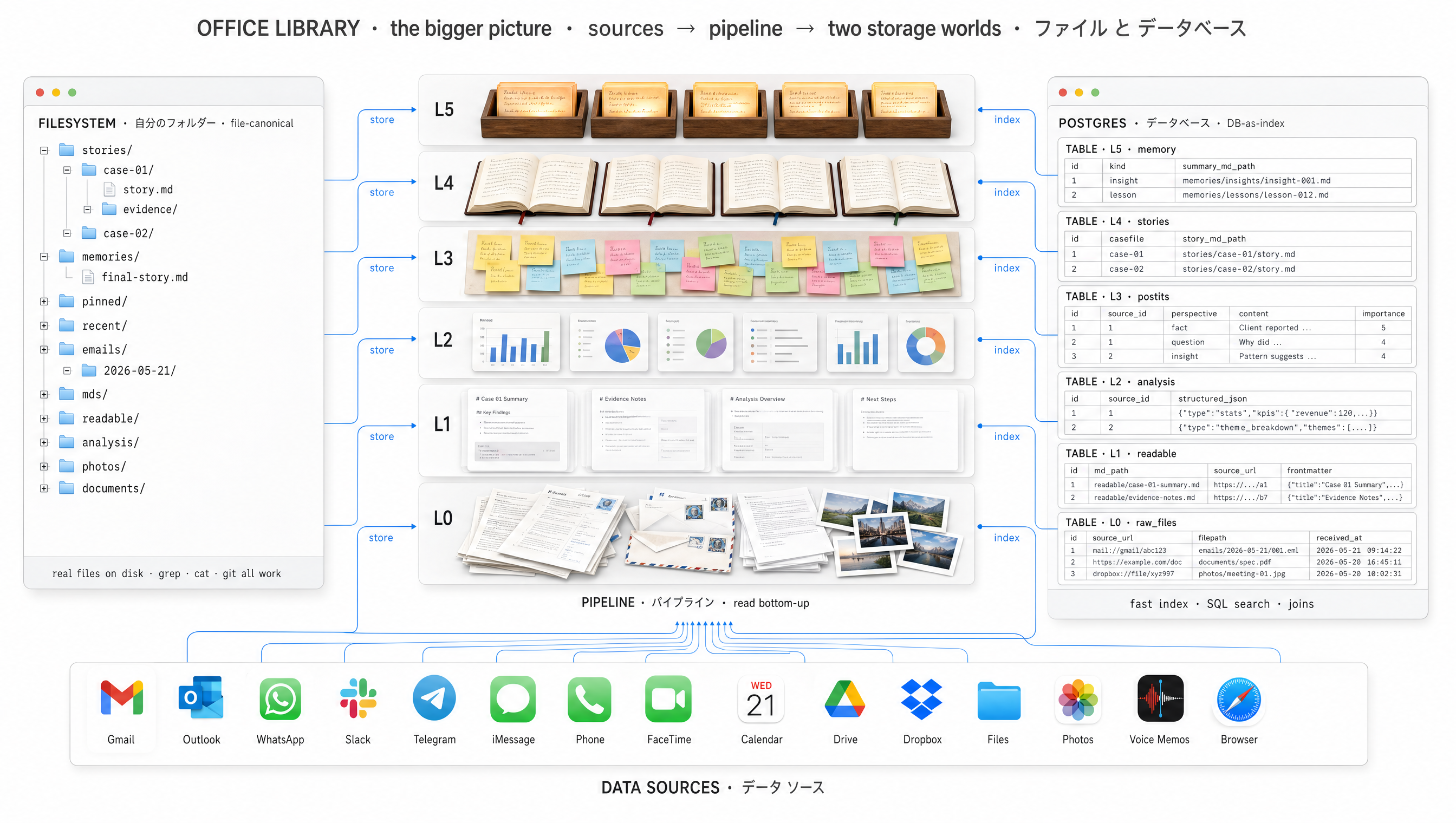
ファイルが正本。データベースは索引にすぎない。
2つのデータベース。5つのステージ。すべてのグラウンドトゥルースはディスク上にある。
データベースを破棄。ディスク上のファイルから数秒でオフィスを再構築。 それがファイルシステム正本(filesystem-canonical)の意味。DBは派生状態。ファイルこそが本物。
2つのデータベース — ワーカー用とライブラリ用
DB A · ランタイム
エージェントDB
誰が今何をしているか。
- エージェント
- ルーチン
- 課題
- 起動
- 承認
- チャネル
DB B · ライブラリ
オフィスライブラリ
オフィスが集合的に知っていること。
- メールとスレッド
- 会話ターン
- ファイル索引
- 付箋
- ケースファイル
- エンティティと言及
ディスク上のファイルはあるべき場所にとどまる — 受信箱、文書、写真、チャットログ。両データベースはこれらのファイル上の索引。オリジナルは決して書き換えない。
5つのステージ — 生証拠から最終ストーリーへ
01
取得
Gmail · Outlook · WhatsApp · ERP · 銀行。生バイトがディスクに着地し、索引行がそれを指す。
02
変換
PDF · DOCX · XLSX · 写真 · 音声 → 生バイトを指し戻す可読な.mdサイドカー。
03
付箋
多くの視点が同じファイルを読む。それぞれが自分のレンズから1枚の短い付箋を書く。
04
ストーリー
付箋がケースファイルごとに集約。十分な新付箋が届くとストーリーが書き直される。
05
最終ストーリー
すべての活動中のストーリーを一つの物語に織り合わせる。毎日書き直し。起動時に読み込み。
どこで作業が行われるか
ランタイム作業
DB Aがパイプラインを駆動
上記の各ステージはDB Aのエージェント行。それぞれがルーチンまたはイベントで起動。
- 取得エージェントはスケジュールで起動
- 変換器は新しい証拠行で起動
- 視点エージェントは新しい可読ファイルで起動
- ストーリービルダーは付箋クラスタしきい値で起動
- 最終ストーリーは日次ルーチンで起動
ライブラリへの書き込み
DB Bがすべてを受ける
各ステージはディスク上のファイルを指す行をDB Bに書く。
- ステージ1 →
files/emails行 - ステージ2 → 行に
body_md_pathを設定 - ステージ3 → 視点ごとに1つの
付箋 - ステージ4 → ディスク上の
story.md、ハッシュはcasefilesに - ステージ5 → ディスク上の
final-story.md、ハッシュはcasefilesに
なぜデータベースの行ではなくディスク上のファイルか
ツールが普通に動く
grep · cat · git · マークダウンビューア · エディタ — すべてネイティブ。オフライン可読
接続不要。サービス不要。ファイルがディスク上にある。
DB災害を生き残る
索引を破棄。ディスクを再スキャン。ライブラリは完全。
来歴がネイティブ
すべての主張はバイトアドレスに解決される — ファイル · 行 · バイト。
共有が容易
メールに添付 · Slackに投下 · 任意のビューアで開く。
軽量なDB
Postgresは索引を保持、内容ではない。小さいまま。速いまま。
このオフィスはどこで動くか
通常のインフラ。Azure、AWS、GCP、または自社データセンター。 文書はファイルストア。2つの索引はPostgres。脳はAPI経由で接続。ハードウェアに魔法はなし — 洗練されているのは各部品の組み合わせ方。
ファイルストアPostgres取得エージェント変換器ファイルシステム正本索引としてのDB
ライブラリはどう構築されるか
エージェントのパイプライン — 取得器、変換器、視点読み手、ストーリービルダー — が生証拠を構造化ライブラリへと変える。各ステージはディスクに書き戻し、来歴は全ステップで保持される。

ステージごと、視点ごと — あなたのアプリが既に生み出すものから、ライブラリがどう構築されるか。
次に読む
すべてのデータ型 L0 · L1 · L2 — 生・可読・任意解析。加えてエージェント自身のチャット。
視点と付箋 L3 — 多くのレンズ、それぞれから1枚の短い付箋。
ストーリー L4 · L5 — 付箋が集約、ストーリーが相互リンク、最上層に最終ストーリー。
オフィスライブラリに戻る 6レイヤーのスパイン。